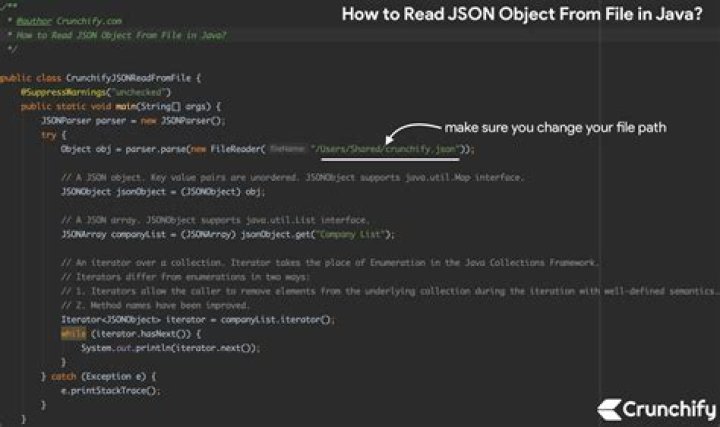
Spark Read JSON File into DataFrame json(“path”) or spark. read. format(“json”). load(“path”) you can read a JSON file into a Spark DataFrame, these methods take a file path as an argument.
How do I open a JSON file in Spark?
Spark Read JSON File into DataFrame json(“path”) or spark. read. format(“json”). load(“path”) you can read a JSON file into a Spark DataFrame, these methods take a file path as an argument.
How do I read a JSON file in Python Spark?
- # Read JSON file into dataframe df = spark. read. …
- # Read multiline json file multiline_df = spark. read. …
- # Read multiple files df2 = spark. read. …
- # Read all JSON files from a folder df3 = spark. read. …
- df2.
How do I read a JSON file in Spark session?
- Create a Bean Class (a simple class with properties that represents an object in the JSON file).
- Create a SparkSession.
- Initialize an Encoder with the Java Bean Class that you already created. …
- Using SparkSession, read JSON file with schema defined by Encoder.
How do I read a JSON file?
- Microsoft Notepad (Windows)
- Apple TextEdit (Mac)
- Vim (Linux)
- GitHub Atom (cross-platform)
How does Apache Spark read multiline JSON?
- import requests.
- user = “usr”
- password = “aBc! 23”
- jsondata = response. json()
- from pyspark. sql import *
- df = spark. read. option(“multiline”, “true”). json(sc. parallelize([data]))
- df. show()
What is the correct code to read employee JSON in spark?
- // Load json data:
- // Check schema.
- scala> jsonData_1. printSchema()
How do I read a file in Pyspark?
- from pyspark.sql import SparkSession.
- spark = SparkSession \ . builder \ . appName(“how to read csv file”) \ . …
- spark. version. Out[3]: …
- ! ls data/sample_data.csv. data/sample_data.csv.
- df = spark. read. csv(‘data/sample_data.csv’)
- type(df) Out[7]: …
- df. show(5) …
- In [10]: df = spark.
How do I read a JSON file in Scala?
- val jsonString = os. read()
- val data = ujson. read(jsonString)
PYSPARK EXPLODE is an Explode function that is used in the PySpark data model to explode an array or map-related columns to row in PySpark. It explodes the columns and separates them not a new row in PySpark. It returns a new row for each element in an array or map.
Article first time published onHow do you parallelize in spark?
- Import following classes : org.apache.spark.SparkContext. org.apache.spark.SparkConf.
- Create SparkConf object : val conf = new SparkConf().setMaster(“local”).setAppName(“testApp”) …
- Create SparkContext object using the SparkConf object created in above step: val sc = new SparkContext(conf)
How do I read multiple JSON files in Python?
- json_data = []
- json_file = “sample.json”
- file = open(json_file)
- for line in file:
- json_line = json. loads(line)
- json_data. append(json_line)
- print(json_data)
What is RDD?
RDD was the primary user-facing API in Spark since its inception. At the core, an RDD is an immutable distributed collection of elements of your data, partitioned across nodes in your cluster that can be operated in parallel with a low-level API that offers transformations and actions.
How do I open JSON files in PDF?
- Install the PDF24 Creator.
- Open your . json file with a reader which can open the file.
- Print the file on the virtual PDF24 PDF printer.
- The PDF24 assistant opens, where you can save as a PDF, email, fax, or edit the new file.
How do I convert JSON to CSV?
- Go to:
- Select “Choose File”
- Click Choose file to upload JSON file.
- After selecting the JSON file from your computer, skip to Step 3 on website and click on “Convert JSON to CSV” or “JSON to Excel”.
How do I read a JSON file in PySpark RDD?
- Create a SparkSession. …
- Get DataFrameReader of the SparkSession. …
- Use DataFrameReader.json(String jsonFilePath) to read the contents of JSON to Dataset<Row>. …
- Use Dataset<Row>.toJavaRDD() to convert Dataset<Row> to JavaRDD<Row>.
How do I query JSON data in PySpark?
- from_json() – Converts JSON string into Struct type or Map type.
- to_json() – Converts MapType or Struct type to JSON string.
- json_tuple() – Extract the Data from JSON and create them as a new columns.
- get_json_object() – Extracts JSON element from a JSON string based on json path specified.
How do I read multiple JSON files in Pyspark?
Using pyspark, if you have all the json files in the same folder, you can use df = spark. read. json(‘folder_path’) . This instruction will load all the json files inside the folder.
What is multiline in JSON?
Spark JSON data source API provides the multiline option to read records from multiple lines. By default, spark considers every record in a JSON file as a fully qualified record in a single line hence, we need to use the multiline option to process JSON from multiple lines.
What is multiline JSON file?
You can read JSON files in single-line or multi-line mode. In single-line mode, a file can be split into many parts and read in parallel. In multi-line mode, a file is loaded as a whole entity and cannot be split.
Which of the following data formats can be read by spark out of the box?
With Apache Spark release 2.0, the following file formats are supported out of the box: TextFiles (already covered) JSON files. CSV Files.
What is spark SQL?
Spark SQL is a Spark module for structured data processing. It provides a programming abstraction called DataFrames and can also act as a distributed SQL query engine. … It also provides powerful integration with the rest of the Spark ecosystem (e.g., integrating SQL query processing with machine learning).
What is Apache spark?
Apache Spark is an open-source, distributed processing system used for big data workloads. It utilizes in-memory caching and optimized query execution for fast queries against data of any size. Simply put, Spark is a fast and general engine for large-scale data processing.
How do I read a Spark file?
- 1.1 textFile() – Read text file into RDD. …
- 1.2 wholeTextFiles() – Read text files into RDD of Tuple. …
- 1.3 Reading multiple files at a time.
How do I read PySpark HDFS files?
Use textFile() and wholeTextFiles() method of the SparkContext to read files from any file system and to read from HDFS, you need to provide the hdfs path as an argument to the function. If you wanted to read a text file from an HDFS into DataFrame.
How do I read a csv file in Python Spark?
- df=spark.read.format(“csv”).option(“header”,”true”).load(filePath)
- csvSchema = StructType([StructField(“id”,IntegerType(),False)])df=spark.read.format(“csv”).schema(csvSchema).load(filePath)
How do you use explode function in PySpark?
explode – PySpark explode array or map column to rows PySpark function explode(e: Column) is used to explode or create array or map columns to rows. When an array is passed to this function, it creates a new default column “col1” and it contains all array elements.
What does explode () do in a JSON field?
You can use explode function to create a row for each array or map element in the JSON content. The explode function will work on the array element and convert each element to a row.
How does explode work in spark?
Spark function explode(e: Column) is used to explode or create array or map columns to rows. When an array is passed to this function, it creates a new default column “col1” and it contains all array elements.
Why we use parallelize in Spark?
parallelize() method is the SparkContext’s parallelize method to create a parallelized collection. This allows Spark to distribute the data across multiple nodes, instead of depending on a single node to process the data: Now that we have created … Get PySpark Cookbook now with O’Reilly online learning.
What is the difference between MAP and flatMap in Spark?
As per the definition, difference between map and flatMap is: map : It returns a new RDD by applying given function to each element of the RDD. Function in map returns only one item. flatMap : Similar to map , it returns a new RDD by applying a function to each element of the RDD, but output is flattened.