For each row N in the source table, UNNEST flattens the ARRAY from row N into a set of rows containing the ARRAY elements, and then the cross join joins this new set of rows with the single row N from the source table. Examples. The following example uses UNNEST to return a row for each element in the array column.
What is Unnest in Presto?
Unnest is a common operation in Facebook’s daily Presto workload. It converts an ARRAY , MAP , or ROW into a flat relation. … The optimized Unnest implementation is available in Presto 0.235 and onward and is enabled by default.
Is Cross join same as join?
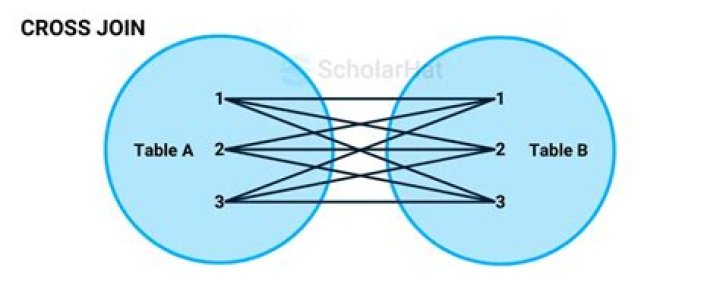
A CROSS JOIN is a JOIN operation that produces the Cartesian product of two tables. Unlike other JOIN operators, it does not let you specify a join clause. You may, however, specify a WHERE clause in the SELECT statement.
What does Unnest SQL mean?
UNNEST. The SQL standard defines the UNNEST function to return a result table with one row for each element of an array.What is Athena Unnest?
The last line contains a lot, but it’s the UNNEST(cities_and_countries. … It tells Athena to for each row, flatten the array cities into a relation called unnested_cities that has a column called city .
Does Presto support correlated subqueries?
I’d love some tips on how I can re-write this to not use a correlated subquery, because Presto doesn’t allow them.
What is cross join?
A cross join is a type of join that returns the Cartesian product of rows from the tables in the join. In other words, it combines each row from the first table with each row from the second table. This article demonstrates, with a practical example, how to do a cross join in Power Query.
How do I Unnest JSON?
The UNNEST function takes an array within a column of a single row and returns the elements of the array as multiple rows. CAST converts the JSON type to an ARRAY type which UNNEST requires. JSON_EXTRACT uses a jsonPath expression to return the array value of the result key in the data.How do you use Unnest?
SELECT FROM UNNEST to the rescue! When you use the SELECT FROM UNNEST function, you’re basically saying, “Hey, I want to UNNEST this repeated record into its own little temporary table. Once you’ve done that, then go ahead and select one row from it, and place that into our results as if it were any other value.”
What is BigQuery used for?BigQuery is a fully managed enterprise data warehouse that helps you manage and analyze your data with built-in features like machine learning, geospatial analysis, and business intelligence.
Article first time published onWhy cross join is used?
Introduction. The CROSS JOIN is used to generate a paired combination of each row of the first table with each row of the second table. This join type is also known as cartesian join. Suppose that we are sitting in a coffee shop and we decide to order breakfast.
Is Cross join bad?
Many SQL books and tutorials recommend that you “avoid cross joins” or “beware of Cartesian products” when writing your SELECT statements, which occur when you don’t express joins between your tables. … That means if table A has 3 rows and table B has 2 rows, a CROSS JOIN will result in 6 rows.
Which join yields more records?
Inner Join can for sure return more records than the records of the table. Inner join returns the results based on the condition specified in the JOIN condition. If there are more rows that satisfy the condition (as seen in query 2), it will return you more results.
What is Unnest in PostgreSQL?
PostgreSQL UNNEST() function This function is used to expand an array to a set of rows. Syntax: unnest(anyarray) Return Type: setof anyelement.
Does Unnest work in redshift?
Redshift does not support any function to unnest or flatten the nested JSON arrays. In order to achieve this, we will have to use JSON_EXTRACT_PATH_TEXT function to load the array which we want to flatten in one column.
How do you query an array in Athena?
To access the elements of an array at a given position (known as the index position), use the element_at() function and specify the array name and the index position: If the index is greater than 0, element_at() returns the element that you specify, counting from the beginning to the end of the array.
What is output of cross join?
The SQL CROSS JOIN produces a result set which is the number of rows in the first table multiplied by the number of rows in the second table if no WHERE clause is used along with CROSS JOIN. This kind of result is called as Cartesian Product. If WHERE clause is used with CROSS JOIN, it functions like an INNER JOIN.
How do you find cross join?
If we use the cross join to combine two different tables, then we will get the Cartesian product of the sets of rows from the joined table. When each row of the first table is combined with each row from the second table, it is known as Cartesian join or cross join.
What is cross join MySQL?
In MySQL, the CROSS JOIN produced a result set which is the product of rows of two associated tables when no WHERE clause is used with CROSS JOIN. In MySQL, the CROSS JOIN behaves like JOIN and INNER JOIN of without using any condition. …
What is correlated subquery in SQL Server?
In a SQL database query, a correlated subquery (also known as a synchronized subquery) is a subquery (a query nested inside another query) that uses values from the outer query. … In the above nested query the inner query has to be re-executed for each employee.
Does Presto support pivot?
You can use the PIVOT and UNPIVOT operators in standard SQL, Hive, and Presto. The PIVOT operator transforms rows into columns.
How do I query with Presto?
Navigate to the Analyze page and click Create. Select Presto Query from the Command Type drop-down list. Query Statement is selected by default from the drop-down list. Enter the Presto query in the text field.
What does the Unnest function do?
The UNNEST function returns a result table that includes a row for each element of the specified array. If there are multiple ordinary array arguments specified, the number of rows will match the array with the largest cardinality.
What is Unnest R?
The tidyr package in R is used to “tidy” up the data. The unnest() method in the package can be used to convert the data frame into an unnested object by specifying the input data and its corresponding columns to use in unnesting. The output is produced in the form of a tibble in R. Syntax: unnest (data, cols )
What is struct in BigQuery?
Definition. Structs are flexible containers of ordered fields each with a type (required) and a name (optional). … In Google BigQuery, a Struct is a parent column representing an object that has multiple child columns.
What is nesting and Unnesting?
Nesting creates a list-column of data frames; unnesting flattens it back out into regular columns. Nesting is implicitly a summarising operation: you get one row for each group defined by the non-nested columns. This is useful in conjunction with other summaries that work with whole datasets, most notably models.
How do I Unnest a JSON in BigQuery?
- Write a SQL model to unnest repeated columns in BigQuery into a flat table.
- Set a relationship between this derived SQL model with the base model.
- Add the derived SQL model in a dataset to expose it to your end user.
What is Unnest couchbase?
The UNNEST clause creates an input object by flattening an array in the parent document.
Is BigQuery SAAS or PaaS?
BigQuery is a fully-managed, serverless data warehouse that enables scalable analysis over petabytes of data. It is a Platform as a Service (PaaS) that supports querying using ANSI SQL. It also has built-in machine learning capabilities.
Why BigQuery is so fast?
unprecedented performance: Columnar Storage. Data is stored in a columnar storage fashion which makes possible to achieve a very high compression ratio and scan throughput. Tree Architecture is used for dispatching queries and aggregating results across thousands of machines in a few seconds.
Why is BigQuery slow?
2 Answers. It’s time spent on metadata/initiation, but actual execution time is very small. We have work in progress that will address this, but some of the changes are complicated and will take a while. You can imagine that in its infancy, BigQuery could have central systems for managing jobs, metadata, etc.