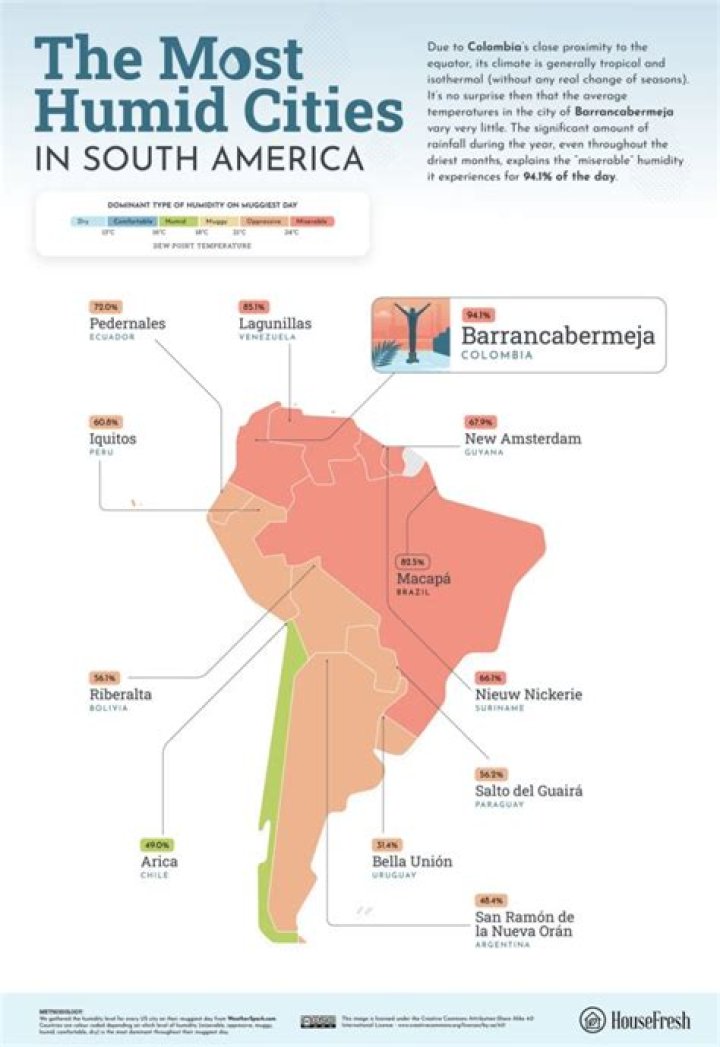
YOLO is an algorithm that uses neural networks to provide real-time object detection. This algorithm is popular because of its speed and accuracy. It has been used in various applications to detect traffic signals, people, parking meters, and animals.
What can Yolo detect?
YOLO sees the entire image during training and test time so it implicitly encodes contextual information about classes as well as their appearance. YOLO learns generalizable representations of objects so that when trained on natural images and tested on artwork, the algorithm outperforms other top detection methods.
Why is Yolo called Yolo?
YOLO or You Only Look Once, is a popular real-time object detection algorithm. … It looks at the entire image at once, and only once — hence the name You Only Look Once — which allows it to capture the context of detected objects.
How does Yolo training work?
A single convolutional network simultaneously predicts multiple bounding boxes and class probabilities for those boxes. YOLO trains on full images and directly optimizes detection performance. This unified model has several benefits over traditional methods of object detection. First, YOLO is extremely fast.What is the difference between darknet and Yolo?
Darknet is an open source neural network framework written in C and CUDA. … The framework features You Only Look Once (YOLO), a state-of-the-art, real-time object detection system. On a Titan X it processes images at 40-90 FPS and has a mAP on VOC 2007 of 78.6% and a mAP of 44.0% on COCO test-dev.
Where is Yolo used?
YOLO is an algorithm that uses neural networks to provide real-time object detection. This algorithm is popular because of its speed and accuracy. It has been used in various applications to detect traffic signals, people, parking meters, and animals.
What are the disadvantages of Yolo?
- Comparatively low recall and more localization error compared to Faster R_CNN.
- Struggles to detect close objects because each grid can propose only 2 bounding boxes.
- Struggles to detect small objects.
How many objects can YOLOv3 detect?
YOLOv3 only predicts 3 bounding boxes per cell (compared to 5 in YOLOv2) but it makes three predictions at different scales, totaling up to 9 anchor boxes.Is Yolo open source?
For those of you who are looking to play around with image recognition in your UAS projects, there’s an open source real-time image recognition system for that.
Why is Yolo faster?YOLO is orders of magnitude faster(45 frames per second) than other object detection algorithms. The limitation of YOLO algorithm is that it struggles with small objects within the image, for example it might have difficulties in detecting a flock of birds. This is due to the spatial constraints of the algorithm.
Article first time published onHow does Yolo darknet work?
How Does YOLO Work? YOLO divides up the image into a grid of 13 by 13 cells: Each of these cells is responsible for predicting 5 bounding boxes. … It applies a single neural network to the full image. This network divides the image into regions and predicts bounding boxes and probabilities for each region.
Why Yolo is faster than R CNN?
YOLO stands for You Only Look Once. In practical it runs a lot faster than faster rcnn due it’s simpler architecture. Unlike faster RCNN, it’s trained to do classification and bounding box regression at the same time.
How long does it take to train yolov3?
Depending on how many images you are training and whether it is on a CPU or GPU, the training time will vary. I trained this dataset on an NVIDIA GTX 1050, and it took me roughly 6 hours. P.S. If you get an error regarding CUDA getting out of memory, try changing the batch size in the yolov3-voc. cfg file.
What is darknet network?
A dark net or darknet is an overlay network within the Internet that can only be accessed with specific software, configurations, or authorization, and often uses a unique customized communication protocol.
Is Yolo an SSD?
YOLO vs SSD – Which Are The Differences? YOLO (You Only Look Once) system, an open-source method of object detection that can recognize objects in images and videos swiftly whereas SSD (Single Shot Detector) runs a convolutional network on input image only one time and computes a feature map.
Who made YOLOv3?
Versions 1-3 of YOLO were created by Joseph Redmon and Ali Farhadi. The first version of YOLO was created in 2016, and version 3, which is discussed extensively in this article, was made two years later in 2018. YOLOv3 is an improved version of YOLO and YOLOv2.
How accurate is Yolo?
In the initial training, YOLO uses 224 × 224 images, and then retune it with 448× 448 images for 10 epochs at a 10−3 learning rate. After the training, the classifier achieves a top-1 accuracy of 76.5% and a top-5 accuracy of 93.3%.
Is Yolo free to use?
Is YOLO object detection free to use in commercial applications? – Quora. A2A. YOLO is open source. You can use it in any way you like.
When should I stop training yolov3?
As a rule of thumb, once this reaches below 0.060730 avg , you can stop training. 0.001000 rate represents the current learning rate, as defined in the . cfg file.
How many pictures do you need to train Yolo?
Label at least 50 images of houses to train the model. Label images of the same resolution quality and from the same angles as those that you plan to process with the trained model. Limit the number of objects that you want to detect to improve model accuracy for detecting those objects.
What is the accuracy of YOLOv3?
Pruned-YOLOv3: analysis and results Hence, the total accuracy of the model is 55.3 mAP for COCO dataset as stated by the author [17].
How is YOLOv3 trained?
Instead of learning from scratch, we use a pre-trained model which contains convolutional weights trained on ImageNet. Using these weights as our starting weights, our network can learn faster.
What is darknet in YOLOv3?
Darknet-53 is a convolutional neural network that acts as a backbone for the YOLOv3 object detection approach. The improvements upon its predecessor Darknet-19 include the use of residual connections, as well as more layers. Source: YOLOv3: An Incremental Improvement.
Is CNN better than Yolo?
The final comparison b/w the two models shows that YOLO v5 has a clear advantage in terms of run speed. The small YOLO v5 model runs about 2.5 times faster while managing better performance in detecting smaller objects. The results are also cleaner with little to no overlapping boxes.
Which is better faster R CNN or Yolo?
Results: The mean average precision (MAP) of Faster R-CNN reached 87.69% but YOLO v3 had a significant advantage in detection speed where the frames per second (FPS) was more than eight times than that of Faster R-CNN. This means that YOLO v3 can operate in real time with a high MAP of 80.17%.
What is the best object detection model?
The best real-time object detection algorithm (Accuracy) On the MS COCO dataset and based on the Mean Average Precision (MAP), the best real-time object detection algorithm in 2021 is YOLOR (MAP 56.1). The algorithm is closely followed by YOLOv4 (MAP 55.4) and EfficientDet (MAP 55.1).
Is darknet fast?
Darknet is an open source neural network framework written in C and CUDA. It is fast, easy to install, and supports CPU and GPU computation.
Is Yolo regression or classification?
YOLO algorithm is an algorithm based on regression, instead of selecting the interesting part of an Image, it predicts classes and bounding boxes for the whole image in one run of the Algorithm.
Who invented Yolo objects?
Joseph Redmon, creator of the popular object detection algorithm YOLO (You Only Look Once), tweeted last week that he had ceased his computer vision research to avoid enabling potential misuse of the tech — citing in particular “military applications and privacy concerns.”
How does YOLOv3 prepare data?
- classes : number of class in your data set.
- train : train file path.
- test : test file path.
- names : class names file.
- backup: where you want to store the yolo weights file.
How do I train my Yolo with my own data?
- Set up the code.
- Download the Data.
- Convert the Annotations into the YOLO v5 Format. Partition the Dataset.
- Training Options. Data Config File. Hyperparameter Config File. …
- Inference. Computing the mAP on the test dataset.
- Conclusion… and a bit about the naming saga.